Abstract
This paper presents a learning-based navigation framework for indoor mobile robots. The proposed method combines a supervised neural global planner, trained from cost-aware A* expert trajectories, with a learning-based local planner formulated as discrete candidate selection over the Dynamic Window Approach (DWA) action lattice. For local planning, the policy is first trained by behavior cloning and then refined by Proximal Policy Optimization (PPO) under feasibility-aware masking. The framework is implemented and evaluated in a simulated indoor environment. Experimental results show that the proposed method generates feasible global routes and reliable local motion commands for safe goal-directed navigation in the presence of obstacles.
Main Contributions
-
1
Neural global planner. A supervised planner learned from cost-aware A* expert trajectories for map-level route generation.
-
2
Learning-based local planner. A local planner formulated as discrete candidate selection over the DWA action lattice.
-
3
Two-stage training. Behavior cloning for initialization, followed by PPO refinement under feasibility-aware masking.
-
4
Reproducible release. A project page for the framework, experiment setup, results, and future code release.
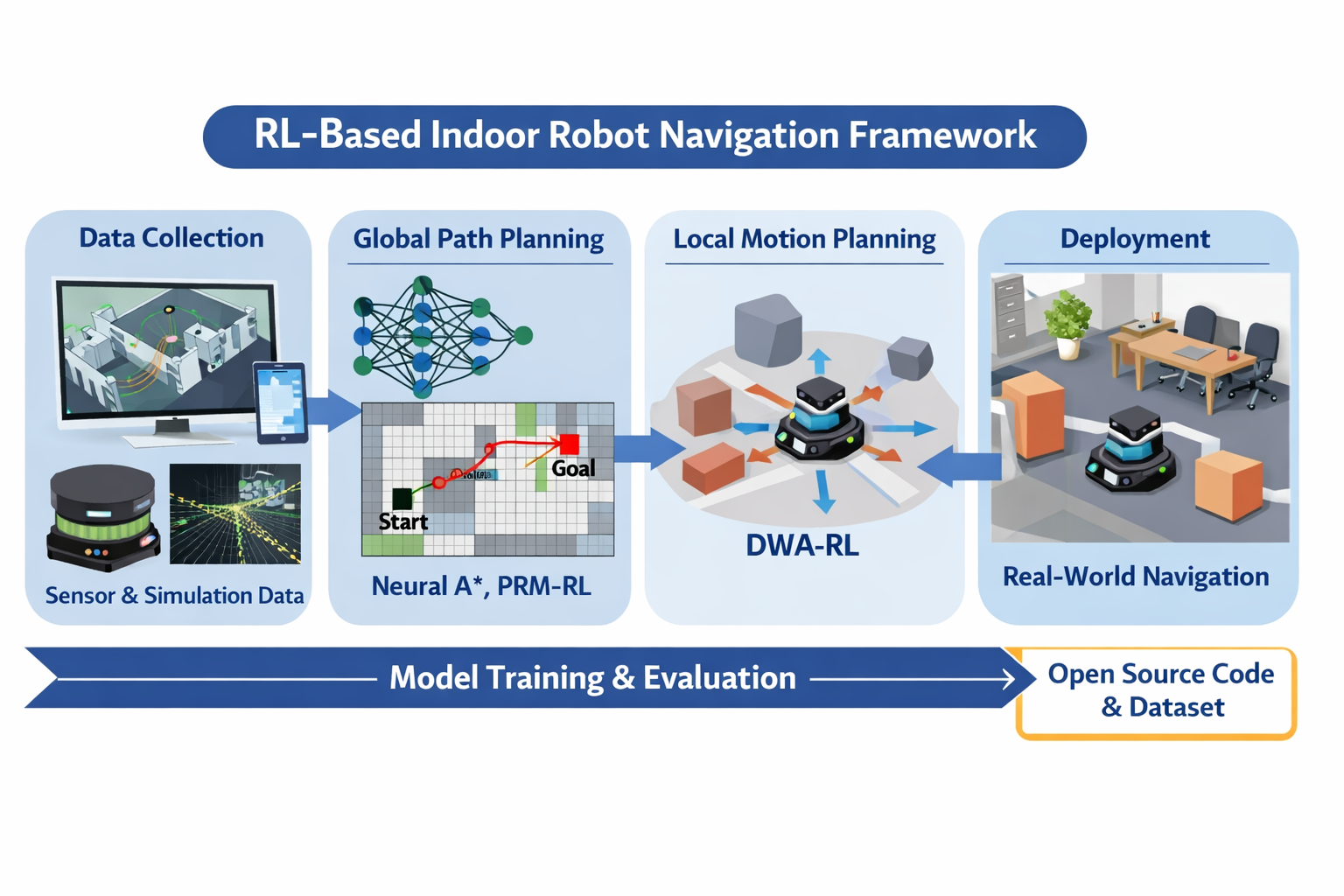
System Overview
Framework Overview
The framework combines a global planner, a local planner, and PPO refinement. The long module list is removed here and replaced by three short visual blocks.
Global Planner
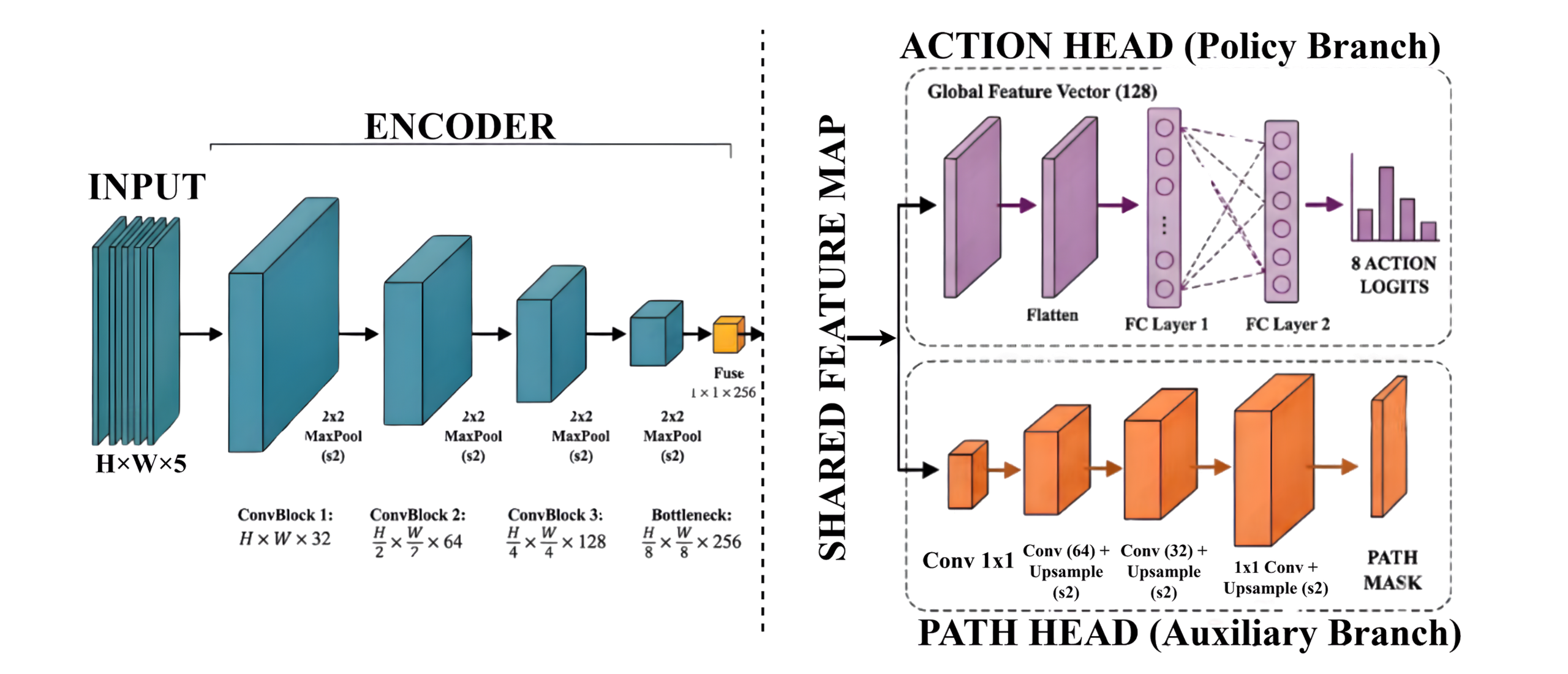
A supervised neural planner trained from cost-aware A* expert trajectories. It predicts one of 8 motion directions from a five-channel indoor costmap input.
Local Planner
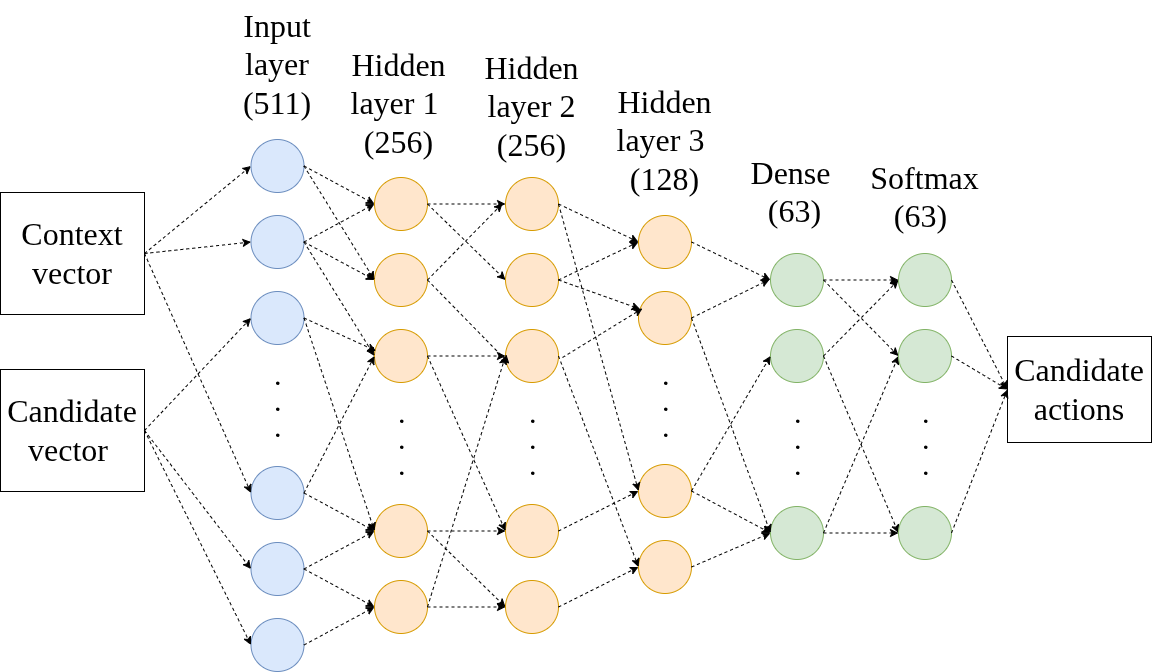
A learning-based local planner that performs discrete candidate selection over the DWA action lattice for path following and obstacle avoidance.
PPO Refinement
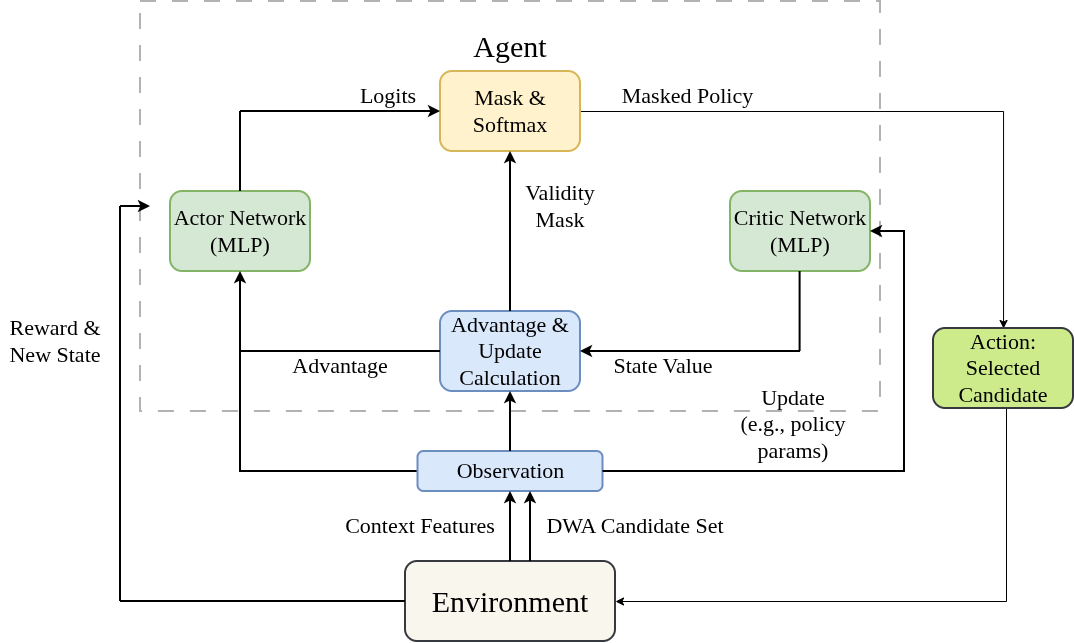
PPO is used after behavior cloning to refine the local policy while retaining feasibility-aware masking over valid DWA candidates.
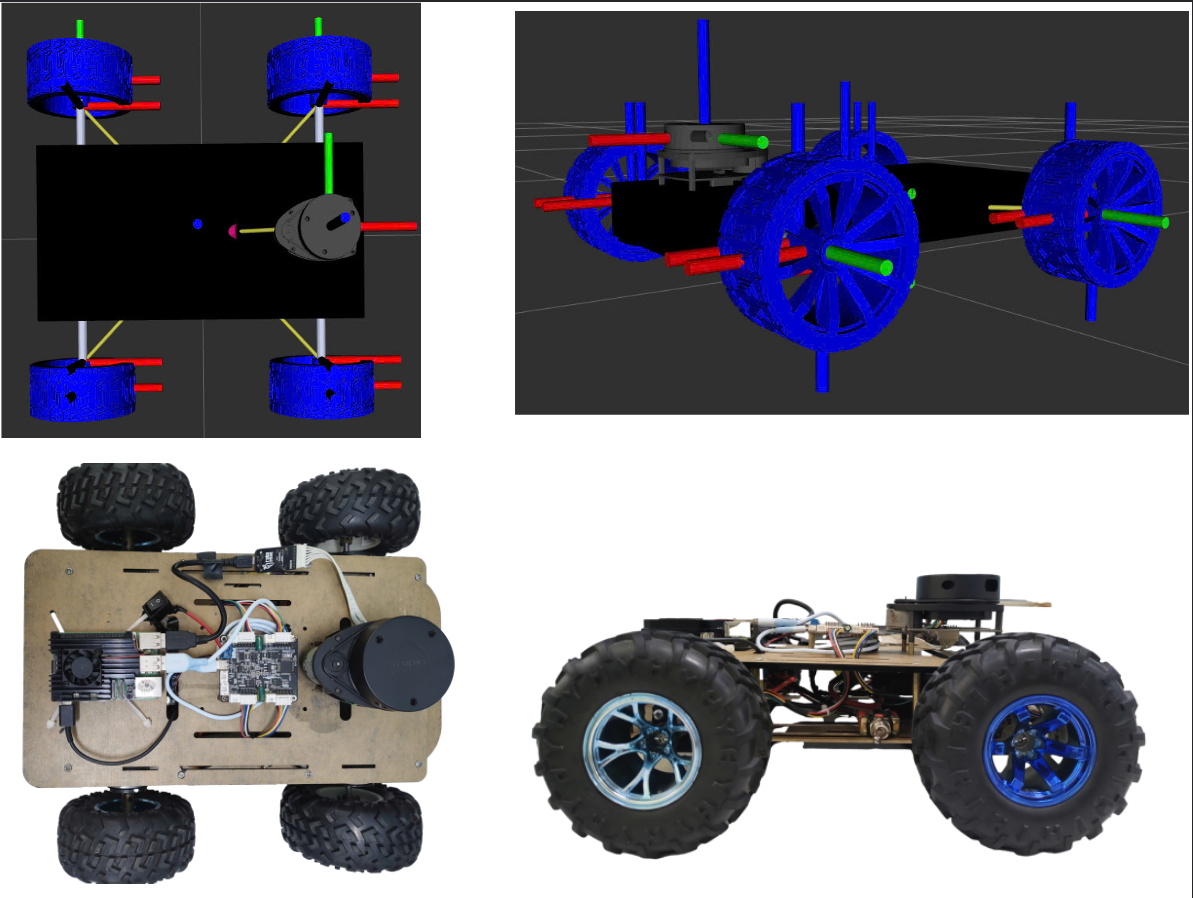
Robot Model and Platform
The system is built on a differential-drive mobile robot. The platform includes both simulation and real-world validation hardware.
-
R
Robot model. Differential-drive kinematics with velocity commands (v, ω) for path following and obstacle avoidance.
-
P
Experimental platform. Real robot with four DC motors, STM32-based control, 2D LiDAR, onboard ROS computer, and laptop-based learning module.
Experimental Results
The paper reports both global-planner and learning-based DWA results in simulation, along with a real-world local-planner demonstration.
Training Setup
Global Planner
Local Planner
Static Scenario
In the static scenario over 10 runs, the Learning-Based DWA achieved better path adherence and lower tracking error, while conventional DWA reached the goal faster.
Obstacle Scenario
In the cluttered obstacle scenario, the learned policy initiated obstacle avoidance earlier, resulting in a shorter path and smoother angular motion.
Video
Simulation Demo
Real-World Demo
Citation
If you find this project useful, please cite our paper:
@inproceedings{nguyen2026learning_based_navigation,
title = {Learning-Based Navigation for Indoor Mobile Robots},
author = {Nguyen, Tri-Tin and Nguyen, Tien-Dat and Le, Gia-Uy and Nguyen, Vinh and Nguyen, Vinh-Hao},
booktitle = {ATiGB 2026},
year = {2026}
}